More than a month since the last update? What happened!?
Well, “Alien Intruder” is progressing nicely: I have 25 stages ready –including playtesting–, and everything else is more or less in place.
The current TODO list is reasonable:
At least another tileset (two ideally), so we can get to 50 stages with some variability to the eye.
Likely another enemy, to make the stages 30 to 40 more interesting.
High score table, because this is an arcade game and chasing score is part of it.
The music, at least: the menu tune, in game, game over, and stage clear. I could also change the tune every 10 stages, but it depends on inspiration writing!
Some more testing!
So is not that much, is it? The engine has been finished for the last month and I have fixed a handful of bugs that necessarily would appear when designing and playtesting the stages, although the “problem” are usually those bugs that don’t present themselves as part of this process, and that’s why we need testing.
I still need to learn to use the Reality AdLib Tracker v2, although I went down a rabbit hole with the music player and I ended implementing a DRO player, so In theory I can use anything that generates AdLib audio and can be captured by DosBox.
There was also a lot of polishing, from improving the asset management –that looks like I almost reimplemented the WAD format–, better memory allocation and far pointer support –ah, isn’t DOS 16-bit fun?–, and small things like saving the joystick calibration to disk.
Anyway, I keep posting updates in my mastodon account –that, by the way, I have moved from SDF; but that is probably a story for a different day–.
My estimation on how long would it take me to complete my current project “Alien Intruder” was a bit off, and it is because I subestimated –or more like I forgot– that I had to write my own sound driver.
In Gold Mine Run! I used the excellent libmikmod, that gives you everything you need, supporting mixing of music and sound effects. Unfortunately for DOS it only supports DJGPP, which is 32-bit, and I’m targeting 16-bit with the IA-16 GCC port.
So I decided I would write my own driver, how hard could it be?
The plan was supporting:
FM for music, via AdLib compatibility.
1 channel 8-bit PCM sound via Sound Blaster.
And I have all that now, but it took me longer than expected because the docs I found were missing small details, and my own incompetence, of course.
Playing an IMF file, like the ones used in “Wolfenstein 3D” for example, is very easy. They are just an array of triplets (register, value and time) that you send to the sound card at an specific frequency, which was my first problem: I didn’t change the Programmable Interval Timer (PIT) chip from the default 18.2065Hz in Gold Mine Run!, and that was fine for MikMod, but not good enough for the FM playback.
So I had to do that, and it took me a bit to get it right because I had something else getting in the way and I though I was reprogramming the PIT wrong.
Which goes back to the default (1193182 / 18.2065 gives us a TIMER_SPEED of 65535).
With that out of the way, we use the interrupt handler to send data to the sound card (those “register and value” from the triplets I mentioned before). And that’s all, other that I need to learn to use a tracker that can export to this format. It will be OK, I’m sure of that.
Programming the Sound Blaster for PCM sound is not too complicated, but it has two parts: setup the DMA (the hard bits), and writing to the DSP (easy and well documented, for example Programming the Sound Blaster DSP).
To keep things simple I’m focusing on “plain” Sound Blaster, without using the new features of later revisions (e.g. the Sound Blaster 16 has other ways of setting up the DMA), and it should work fine with most configurations, but I kind of expect things to be a bit standard via the BLASTER environment variable. For most people playing the game with DosBox it will be fine, and I don’t need to support all the weird configurations out there.
There were two gotchas in this part:
the memory used by the DMA can’t cross a 64k page physical boundary.
for whatever reason, when I used a large buffer for the DMA(say 48K), I got pops and weird noise in some samples.
My first big mistake, that took me some time to fix, was that I’m using DOS’ int 21h service 48h to allocate memory, and that returns a segment. So if you ask for 64k, that won’t cross a page boundary, right? Well, that is not correct, the page you get is virtual.
The way to calculate and find the page boundary is using a 20-bit memory address. If the end of our buffer is on a different segment on that 20-bit address, we are crossing a boundary.
A simple way of dealing with this is allocating double the memory you need (for example 32K for a 16K buffer), and if the end of the first 16K are on a different segment, just use the second 16K that are guaranteed then to fit on a 64k page.
/* falloc is my own "far alloc" as I implemented far pointers */ dma_buffer = falloc(MAX_SAMPLE_LEN *2);
if (!dma_buffer)
return0;
dma_start = dma_buffer;
/* 20-bit address */ dma_linear = (dma_buffer >>16) <<4;
/* avoid crossing a page boundary */if ((dma_linear >>16) != ((dma_linear + MAX_SAMPLE_LEN) >>16))
{
dma_linear += MAX_SAMPLE_LEN;
dma_start += MAX_SAMPLE_LEN;
}
/* these won't change */ dma_page = (dma_linear >>16) &0xff;
dma_offs = dma_linear &0xffff;
I keep dma_buffer unaltered because I need it to free the memory with DOS later on, but my working buffer is really pointed by dma_start. Also the DMA works with the 20-bit address (also called linear), so I pre-calculate the values here.
After this is just matter of copying the sample I want to play (in my case MAX_SAMPLE_LEN is 16K), setup the DMA to use the buffer and the right size (depending on the sample), and ask the DSP so play it.
I implemented a simple priority based playback, like I do in my 8-bit games, so a sample plays only if there is nothing playing already, or the sample you want to play has higher priority than what is currently playing.
I track what I’m playing by setting a variable when I start playing a sample, and clearing it when the IRQ interrupt is triggered by the sound card when it has finished playing a sample.
With this priority table, the action sounds fine with only one channel and saving myself from doing mixing of multiple channels:
Initially I thought I could load all my samples in a 64K page –being careful with the size of the samples–, and play them from there; but for whatever reason, even if the memory is not crossing a page boundary, the playback isn’t right and there are unexpected pops or noises in real hardware (emultted) but not in DosBox (that is more permissive). I don’t know what is this, and I can only test with the excellent 86Box, so I decided to use a smaller buffer and just copy there the sample I want to play. After that, all plays and sounds as expected.
I’m assuming this has a performance hit, but so far the game plays nice on a 286 –as long as the VGA card is decent–, so I’m not concerned.
Anyway, I didn’t want to make this a tutorial, and is not; but I explained a bit what I have been doing. The game is progressing nicely, but I’m not going to suggest any release date this time!
I mentioned recently a couple of DOS game jams, and I’m working on a game that it was a good match for the first one because I’m targeting 8086 and VGA, but I couldn’t finish it on time. That’s OK, I thought, because I can submit it to the next jam.
Unfortunately, I don’t think I’m going to get to that one either –there are 4 days left until the deadline and the game is like 40% done–. I will finish the game anyway and release it, as I did with Gold Mine Run! last year. The game it even entered a DOS Game Jam compilation CD, although it was never submitted to the jam. Which is awesome, although there aren’t that many new DOS games released every year, so if your game is not a total disaster, you should get some attention –and players!–.
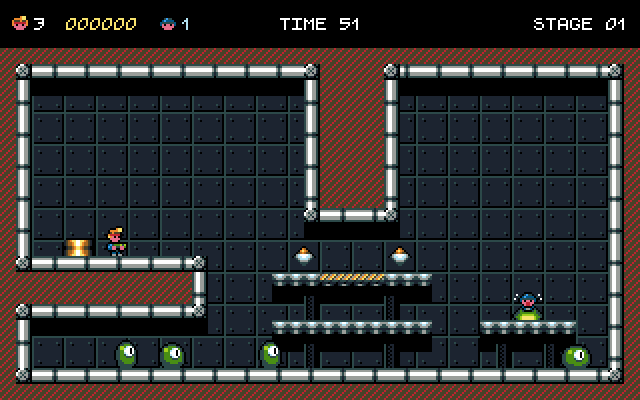
Anyway, let me introduce you to my current project: Alien Intruder.
The work in progress of the menu screen
Testing in-game screen
There are still some unknowns, but I can already say the following:
For MS/DOS or compatible
Requires IBM PC/AT 8086 or later (a 286 is recommended), with VGA
Controlled with keyboard or 2 button joystick (2nd button for jump)
AdLib and/or SoundBlaster (undecided yet)
I am exploring some ideas, but it will be a “jump and shoot” type of arcade. I know this will fuel those saying that I am making too many arcade games, but they are obviously wrong :P or haven’t played my latest game: The Heart of Salamanderland, that is not an arcade.
The code is using all I learned making “Gold Mine Run!”, but also The Return of Traxtor. This is because my library for DJGPP requires a 386 and protected mode, but in this game I’m using 16-bit and the IA-16 GCC port, so the code I wrote for “Traxtor” is very relevant.
It took a bit of work, but I managed to simplify and port the VGA code to run in 8086 using a “small” memory model: independent segments for code and data, which means 64K of memory for each, and allocating 64000 extra bytes via DOS so I can have a back-buffer.
And the result is better than I expected! It even runs OK on very underpowered machines if we limit the number of entities. I tried for fun emulating a Sinclair PC200 using 86Box because it was the first PC my cousin had, and it was easier to boot with VGAcompared to other IBM PCs of the time –part lack of skills on my part, and part because I couldn’t find the right MS/DOS version to boot–.
Obviously the VGA is kind of expensive because each pixel is a byte, so I knew I couldn’t target those early models and make the type of game I was planing to make, but it was a fun test even if at the end a 286 is a more reasonable requirement. For most people I assume this won’t matter because it will run just fine in any modern machine with DosBox.
I can’t say for sure when it will be finished, but I am guessing early September is perfectly possible.
Last year I released two new DOS games (Gold mine run! and The Return of Traxtor), both made in the context of a game jam, even if I don’t really do game jams anymore.
Anyway, it was a lot of fun and it pushed me to get up to speed with the DOS platform, remembering in a way what I knew back in the late 90s, and going beyond that. And there are more DOS jams in 2024!
There could be other jams this year, like the DOS Games Jam –that had its first edition in 2020–, but these two jams tick a couple of boxes for me:
The target platform must be DOS (in other game jams is more about the feel, but I prefer going a bit more retro and make a game that runs on the actual hardware).
There are some interesting limitations, being 8086code in one of them (meaning: Intel 16-bit), and a COM file the other one (all the game must fit in 64K).
Since I released The Heart of Salamanderland for the Amstrad CPC last month I’ve been going through some ideas for potential games, and I was suffering a bit of choice paralysis and not starting anything (neither continuing one of the on hold projects).
When I released Gold Mine Run I put together a DOS library to make games with DJGPP, which is 32-bit and not useful for any of these two jams. But because I made Traxtor targeting the IBM PC/TX, I have some interesting code that I can reuse.
I’m toying with the idea of making something for the first jam, although I’m not sure what I’m going to target yet. I don’t feel like doing CGA again –too soon, and it is hard to draw nice things I guess–, EGA is such a pain to program, and VGA may not be a great match for the jam’s limitations.
Fusion Retro Books, besides of publishing very nice retro-computing inspired books, has been reviving some of the old magazines that were popular in the United Kingdom in the 80s. That is Crash for the ZX Spectrum, Zzap!64 for the Commodore 64 and Amtix for the Amstrad CPC.
If I’m not mistaken, it all started with annuals for the speccy and the Commodore, that were (are?) like a slightly larger magazine on a nice hardback edition that covers games released on the last year –with exceptions, they also cover new games that were released before the annuals were a thing–, and because we were living a retro-boom and the annuals were successful, Fusion got the rights for the magazines and started publishing them in a small A5 format with 60 pages.
Looks like, of the three, the Amstrad CPC is the smaller –or less active– community of users, so when Fusion was touching base trying to find if there was enough interest to sustain a Amtix revival, I was supportive of the idea –and excited!–. But as I recall it, the response from the community was lukewarm at best.
Hyperdrive was reviewed in Amtix #7
There were different reasons. For example, some people didn’t like the original Amtix, so I thought it was not going to happen. That’s why we can’t have nice things, etc. But it finally happened, and Fusion decided to give it a go with 12 numbers, and depending on the support, perhaps keep going.
We just got the 12th and last issue of Amtix CPC, and I’m not surprised.
I do think that the Amstrad community is sometimes weird, and not that different from other retro-communities in reality. We see that with new games, when people are very quick to ask for physical releases of the games, but very often the sales of those editions don’t justify the effort –and I’m not talking about profits but to just break even–, or even with people looking forward to play the game when is in development, but when the game is released… silence.
I find this frustrating, but what can be done? The ones wishing there were more things happening around the Amstrad CPC are not always the same that won’t support those initiatives, and being a smaller community perhaps than the ones behind the ZX Spectrum or the Commodore 64 (or the MSX!), means that we have less options (physical editions, magazines).
Although all this is true, in the case of Amtix, I think there are other reasons at play.
In my opinion the magazine was a bit hit and miss, and this is probably not unique to Amtix. I was subscribed to both Amtix and Crash, and by Amtix issue 7, I decided to cancel my subscription because I wasn’t enjoying reading the magazines.
What didn’t work for me? I guess it was a mix of different things: layout problems, some of the texts were very amateur, reviews of games that shouldn’t be there –a free game that is not good, why waste pages on it when there are more games to review?–, and in general it felt like they wanted to revive exactly what those magazines were in the 80s without realising that we live in a different time.
Yes, I know. But I said it already, the Amstrad community is sometimes weird, and I’m part of it.
Perhaps it could have been better, or different, but I’m glad we had Amtix back even if it wasn’t perfect. You can still get the magazine from Fusion Retro Books pages on Amtix CPC.
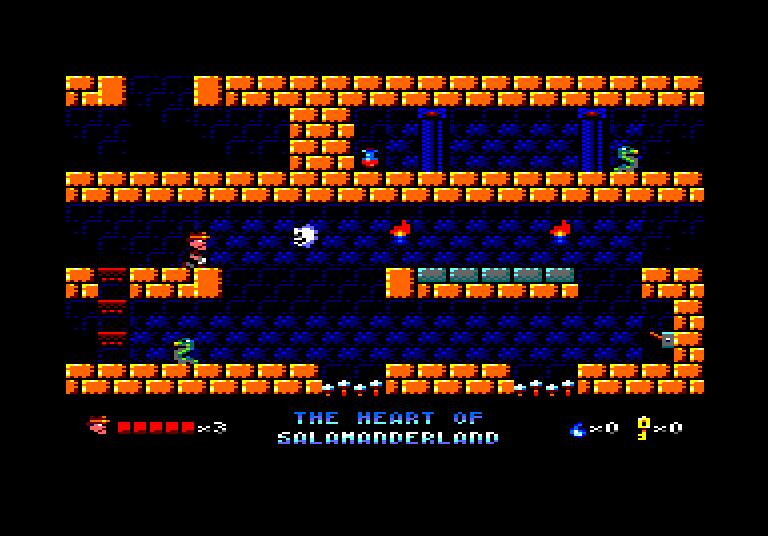
I announced here last year in December that I was working on a new Amstrad CPC game, although I had started the project in November. I’m still quite hesitant to announce a new game until I know I will finish it, despite doing this for almost ten years now.
The game is essentially what I planned: whip action fighting enemies, a good sized dungeon to navigate, and levers and keys to implement some basic puzzles. Which is always a bit of a refreshing surprise because very often the finished game is not quite what I had in mind when I started the project.
I took some risks on this one, by using an engine I wrote for performance, but that requires a lot of memory for a 64K game –essentially 16K for the hardware back buffer–, and that can always affect the size of the resulting game.
I put a lot of time into the encoding of the screens, using a new idea I had never implemented before based on meta-tiles of variable size –a bit more advanced than what I described here–, and at the end I managed to cram in 6 different enemy types with their own behaviour, a final boss, 55 screens and 4 music tunes –menu, in-game, game over and boss fight–.
In reality is not that you have 64K, it was in this case 32000 bytes of usable memory, and I finished the game having 162 bytes left. It was a tense when I had to fix a couple of last minutes bugs!
One of the screens on the game
The game is framed in the world of fantasy of my 7 years old son, mixed a little bit with the universe of the Fablehaven novels by Brandon Mull, that happens to be mostly “compatible”.
You could argue that is not that important, because we all know that what it was written on the inlay of the 8-bit games from the 80s was just some filler that may or may not fit the actual game, but in this case it was an important source of inspiration when designing the enemies and the mood of the game. I don’t know if I succeeded, but my son is happy with the result, and that’s the gold standard for Salamanderland!
I made some decision regarding gameplay that I knew that could be controversial: tight jumps –I implemented “coyote time”, so it shouldn’t be that hard–, and classic “3 lives and game over”. It is an 8-bit game, these shouldn’t be a problem, isn’t it?
My hope is that players will persevere and get to enjoy the game for what it is. Of course there will be people that will get frustrated and quit, but that’s something that can always happen, no matter what game you make. If you can’t make everybody happy, be sure it is you that is satisfied with the result.
The game can be downloaded and played for free here: The Heart of Salamanderland, and a physical edition by Poly Play is planned for later this year –more information about that soon!–.
There is a delusion that “maintained” open source software comes with entitlements – an expectation that your questions, bug reports, and feature requests will be attended to in some fashion.
I couldn’t agree more, as I experienced that myself a few times. Including some people being a bit too pushy for my personal taste, so that I accepted patches and features because my project was upstream for them, and it is obviously better if I maintain those changes instead of them keeping track of my project as a soft fork.
Some of those changes, I accepted them. I recall for example scp support in a sftp proxy for OpenStack Object Storage, despite scp not being part of sftp really. Although I knew I was not going to use that feature, and I was very sure I didn’t want to maintain it.
The consequence is that it makes the maintainer less happy and, although I was employed by a company for which I was maintaining that open source project, it didn’t feel right and made me double-think if I really wanted to release more open source projects.
I recall reading a blog –can’t find the link– where the author said that they would never release anything that is useful, so they don’t get bullied into maintaining it after that. It sounds a bit extreme, but makes a lot of sense.
Matt includes in his post what he calls The Open Source Maintainer’s Manifesto:
I wrote the software in this repo for my own benefit – to solve the problems I had, when I had them. While I could have kept the software to myself, I instead released it publicly, under the terms of an open licence, with the hope that it might be useful to others, but with no guarantees of any kind. Thanks to the generosity of others, it costs me literally nothing for you to use, modify, and redistribute this project, so have at it!
Perhaps I don’t fully share the tone in which he wrote the whole piece, but that’s the gist of it: when I release something as open source, I see it as a gift to everybody, and the licence makes it crystal clear what anyone can expect from it. Yet, it is difficult.
I wasn’t happy with some of the contributions to my ubox MSX lib project, and didn’t accept them –which ended in a fork, that’s OK!–. Other changes, I accepted them, and I’m still unhappy about it because it wasn’t really why I released that code as open source after a lot of work to document and prepare the whole thing.
So it may seem I’m making things more complicated to get contributions now that I’m self-hosting the project out of a forge –it was in GitHub, then in GitLab, and now I self-host it–, but in reality I’m just keeping in the open something I made for myself and I’m sharing with the world.
But is not really a product, and I don’t want it to be. Thanks!
2024 is the year Corporate open source—or at least any remaining illusions about it—finally died.
It’s one thing to build a product with a proprietary codebase, and charge for licenses. You can still build communities around that model, and it’s worked for decades.
But it’s totally different when you build your product under an open source license, foster a community of users who then build their own businesses on top of that software, then yoink the license when your revenue is affected.
That’s called a bait-and-switch.
The list of formerly proprietary software now open source is longer, but that can be explained because often times a project that is dying commercially, becomes open source and community managed.
And someone shared in mastodon a post from a couple of years ago drones run linux: the free software movement isn’t enough by Jes Olson, that mixes probably too many things –including ethics that have been never part of free Software, and perhaps they should–.
Not a verbatim quote, I formatted the text (go and read the original post):
Groups of capital formed, and two libertarians started the open source movement as a corporate-friendly free software alternative.
And they won.
And later on:
The accidental benefits of the free software movement: a global community working asynchronously, sharing code without pay. These important, critical benefits, which were responsible for the absolute dominance of things like gcc, the gnu coreutils, and Linux - have been hopelessly devoured. All they had to do was strip away the pesky moral movement that all of these efficiency gains carried with it - and voilà. Money.
The post is very negative and defeatist and, although I don’t agree with all the points, it resonates with me in I way I wasn’t expecting: from how hard is not using non-free Software –although less today than 20 years ago–, to how the mainstream mood is aligned with the corporate view of open source –every open source project must be a product produced industrially and exploitable by businesses–.
Yes, the free Software movement was colonized and, at the end, we only have GitHub and permissive licences. And they told us we had won because “even Microsoft is doing open source”. But, did we?
I moved SpaceBeans back in June 2023 –as I wrote self-hosting git repos for now–, and I kind of put off moving my MSX project because having more users I thought it would be harder. But I was wrong!
SpaceBeans has binary artifacts, that I have to build and host somewhere, and back in GitLab, that was mostly automated and managed by CI (Continuous Integration). And in my mind, ubox MSX lib was that, and more –because the users–.
I was probably right about the users, but ubox MSX lib doesn’t have a binary that needs to be produced and distributed. Instead, the project’s output is just the source code, and in that case cgit has you covered using the refs view where you can download a zip or a tar.gz of any of the tags. And that’s all!
So the project is out of GitLab now. I put an announcement on the GitLab’s repo, and archived it so it is preserved read-only. And, obviously, things are going to work slightly different:
The project can be cloned only via https only with: git clone https://git.usebox.net/ubox-msx-lib.
Contributions are now via email, or alternatively you can make them available on a public repo so I can pull from it.
The project home is the same, ubox MSX lib in usebox, with news and the documentation for easy access.
The only thing that is currently missing is a shared public channel for communication and collaboration, that previously was GitLab’s issues and merge requests. I know things can be more difficult now, for several reasons, but mainly because the way I want to work now is not following the mainstream forge model that you can see in GitHub, GitLab, Codeberg, and others –you can even self-host projects like Forgejo–.
Nothing is set on stone: if necessary, I could setup a mailing list somewhere. I’m not doing it for now because it doesn’t look to me like this project has that many contributions that the resource would be used.
I’m planning a 1.2 release, adapting the project to work with the latest SDCC and its new calling convention, which will be a big change because people using the older SDCC will stay in current 1.1.14 version.
Meanwhile, there is an active fork by robosoft, in case you want and advance of what that 1.2 could look like (also it includes some MSX2 related changes that may interest you as well). Let’s keep those MSX games coming!
I like programming languages, and since I attended University many years ago, I’m attracted to their design and implementation. For example, I talked here about Micro, which I think is my latest complete release on the topic.
But implementation of programming languages is complicated, and takes a long time. That’s OK, however I think I always make the same mistakes.
To start with, I tend to implement a language that is too big. I try to do everything “the right way(tm)”, which takes even longer, and in the case of compilers, when I get to the parts that I don’t have experience and I really should investigate more, I’m overwhelmed and out of energy.
So last week I was busy and tired, and frustrated, so one night I started a new project to see what I could do in a few hours, with the following conditions:
It doesn’t have to be nice, or well done. For example: error reporting? where we are going we don’t need error reporting!
Build an interpreter first, we’ll see if it is worth adding code generation (compiler) later.
Use tools that I know well already.
Keep everything small, so it is easy to change direction without a lot of refactoring.
And that’s how Funco came to be. It is very small, written in Python (3.10 or later because I used match), it is only an interpreter taking from Python everything I could, and the user interface is very rough (raising exceptions on errors!). But it works, and it was very satisfying to write, even if it is not very useful other than helping me to solidify what I already knew.
It is inspired by lispy and Atto, and it looks like this:
# example of a factorial functiondeffact(n acc)
if=(n 1)
acc
else# tagging a tail call with "@" so it can be optimized @fact(-(n 1) *(acc n))
endend# main is the entry point of a programdefmain()
display("Running fact(50)...")
display(fact(50.1))
end# output:# Running fact(50)...# 3.0414093201713376e+64
It is functional, with no variables, and well… almost everything is a function –I excluded function definition and conditionals to make it easier to use–. It feels very Lisp, and the syntax is a bit Ruby-like (which is useful so get syntax highlighting).
You won’t find anything revolutionary in the code, but that wasn’t the point. I even implemented recursive tail call optimizations, because otherwise it wouldn’t be useful at all given that the loops are implemented with recursivity. For example:
# recursive for loopdefrecfor(n fn)
if>(n 0)
fn(n)
@recfor(-(n 1) fn)
endenddefmain()
recfor(10000 display)
end
Because there is no “return”, it is required to tag the tail calls with @ so the interpreter tries to optimise that call avoiding hitting a stack limit (and improving performance, although speed was never in my plans).
Perhaps I will put some more time to add nicer error reporting, just in case I can use this funco as a base for future experiments. Now that I have something small and easy to modify, it shouldn’t been that costly to make small experiments with code generation!
Edit (2024-04-29), I have added more examples. It is a toy language, but there is some brain teaser about writing these that I like.