I know I wrote “remote” on the title of this post, but I have this theory that what I’m going to discuss here is not really a problem with remote pair programming, but with pair programming itself.
In my team we do pair programming, and we like it. We are completely on board with the benefits, and we are happy to assume the few small costs that come with it. Of course, with the COVID situation we have been working from home for over a year now, and we have been doing pair programming remotely; including with team members that have joined the company (and the team) remotely, so we haven’t met in person.
And we have made it work, essentially, using Google Hangouts sharing the screen –which is not very good to be honest, in my experience Skype provides better video quality with less bandwidth–, and that’s basically it. It is exhausting, but in my experience I wouldn’t say more than non-remote pair programming sessions.
Unfortunately this is somewhat limited, because it means that one person is driving, and the other person is in the back-seat. Not having the keyboard doesn’t mean you are not actively contributing, but taking turns driving is too awkward because the code has to be made available to the other person, for example via a WIP branch on a git repo.
There are better options, that allow easily taking turns, or even work on the same code at the same time collaboratively. Some examples of these tools are:
tmate: for any terminal based editor and tmux aficionados.
Live Share: for VS Code only, that allows collaboratively edit and debug in real time.
There are a few more options, but these are probably the most popular in my circles.
Looking at my team, we have a very diverse set of skills, and we use very different editors: one vim, one emacs, and two VS Code.
I think it is pretty clear what is the issue if we try to take turns driving a pair programming session, isn’t it? And I have the theory that this is not really a problem with the remote part of it.
I’m sure we would have the same problem if we were in the same office, sharing keyboard an mouse –which I don’t find comfortable at all–. Am I proficient with emacs or VS Code? No, I’m not.
I remember attending a conference back in Guildford –if I recall correctly–, and there was a talk by someone from Pivotal Labs. It was more like they were selling some product, but I remember clearly how they explained their experience with pair programming, and how one of the requirements was that there was one editor, with one configuration, and all the software engineer seats were exactly the same, without any customization.
The idea was that any developer could use any seat to write code like they were on their own computer, basically because all computers were the same (and I may add, they would love if all their engineers were the same and replaceable).
I found that fascinating, and of course I would never want to work on a company like that. By stripping all engineers of any personality and any chance to express themselves through their tools and whatever makes them productive and happy, they optimised their teams for pair programming. I’m not even sure that’s good for the company.
So we keep looking around and checking tools periodically, but I suspect we are not going to find a solution. Because it may come with a price –like the case of Pivotal– that we may not want to pay.
This is my second open source release after I made public the code of Castaway, for the ZX Spectrum. Looks like there is a trend now!
This one requires SDCC to build, plus some other requirements for different tools. The idea is not to provide a current version of the game, but the game as it was built back in 2015. That means an old version of SDCC is required, mostly because at some point the project changed some of the tools to manage libraries, and that change wasn’t backwards compatible.
This is probably OK because the old versions of the compiler are still available, and the game’s source code is interesting mostly as a reading exercise anyway. The only big warning is that some of the dependencies have bugs that have been fixed in later releases, so if you want to start a new project, don’t use the versions included in this repo!
Surprisingly enough, this project doesn’t have anything really embarrassing, although is not what I would call a “current” code base. It is poorly organised, with one big file, and SDCC is not the fastest compiler out there. Despite that, overall I think it is still very readable and could be useful to learn a bit about making games in C for the Amstrad CPC.
When I was testing that the game was building correctly, I’m pleased to say that it is still fun puzzle game with cracking music (if I say so myself).
Finally, I don’t plan to provide any support. I know I said that when I released Castaway and then I accepted a contribution to make the codebase compile with a current version of Z88DK; but I really mean it: if you want to compile the game, you are on your own! There may be some bumps, but take it as part of the learning experience.
This week has flown by, and my day job has been quite draining, but today is Thursday and that means gamedev update!
Released my ZX Spectrum 48k beeper engine
That could explain why this week I have been a bit low, because working on this little project was kind of intense, and when one of those ends, it always leaves some emptiness.
Although it is ready to use, there are some things that I may probably add later on:
More ASM versions of the player. Currently I provide the primary source for he SDCC assembler, that is not the most common syntax. I hope other people using it will contribute other versions.
Currently the player doesn’t preserve the border color (and there’s a FIXME for that). I may or may not use that, but I guess it is something that is missing for general use.
Everything else is in place and working, to the extent that I have tested it, of course. I’m mostly concerned about the editor having bugs, but I will fix those when they are reported.
Investigating a scripting solution
Although most of my games are very data driven, I have never implemented scripting for any of them. We are talking 8-bit games here, so is not about making the games extensible, but to save memory by using very high level functions in a very dense virtual machine (the script would be more like bytecode).
This solution is very close to the data driven approach I’ve used for example in Rescuing Orc and Dawn of Kernel, were all the data is entered using tiled, and then packed into binary by a Python script.
A text event in Dawn of Kernel
In Dawn of Kernel for example, there’s a “text” event that, when present, it will display a message from Kernel –the enemy IA–. That saves space and makes game design easier, but there’s no game logic on that data, and that’s something the scripting engine should support.
In reality I should start a project, and then look to implement a simple scripting engine if I need it. Ah, if only things were that simple!
Anyway, I’ve always been into programming languages –specially compilers and interpreters–. Together with operating system design, those topics were my main interest back in Uni. Fortunately I gave up with the operating system part, but every now and then I have the itch to implement a programming language. From silly toy languages to a 6502 VM for 8-bit AVR, so getting myself to write such an engine can be dangerous for my free time!
For now I’ve looking to some interesting resources:
A high level language to access and manipulate game state.
A compiler to translate that language to bytecode.
Execute the bytecode in a tight VM, written in the target platform (likely to be Z80).
Integrate the VM in the game loop.
I’m not sure if is worth moving all the entity information I usually encode in the map data into this language, because the way it works now is very optimal and I really like using tiled to place the entities in the map –it makes game design nicer–. Perhaps this is about including labels on the script and refer to those labels in the map data, so a part of the script is run as an entity. That could allow supporting game logic easily, keeping the benefit of both approaches.
Hopefully I’ll start a project soon and we will see if any of this makes any sense!
Is it Thursday? No, but is close enough to see what happened this week in gamedev!
ZX Spectrum 48K beeper engine
I have always been fascinated by the different beeper sound engines produced in the 80s for the ZX Spectrum, and some of the modern ones too –see the work of utz/irrlicht project–. It is truly amazing how that sounds, considering that it is 1-bit audio.
Until now I was happy using the tools/engines released by Shiru, his BeepFX is probably the best you can get in 1-bit audio. There is a downside though, because to reach that level of sound quality, it has to use all the Z80 CPU actively, and that means interrupting your game. If the sounds are short enough is OK, but not perfect.
So a potential solution to this is running a beeper engine from the interrupt, which means the sound quality will be low because the Spectrum has only one interruption at 50Hz, and limiting the time you spend by frame so the sound won’t interrupt the game’s action (noticeably, at least; we know the interrupt interrupts). And you can also stop the sound being played, replacing it with another sound every 50Hz.
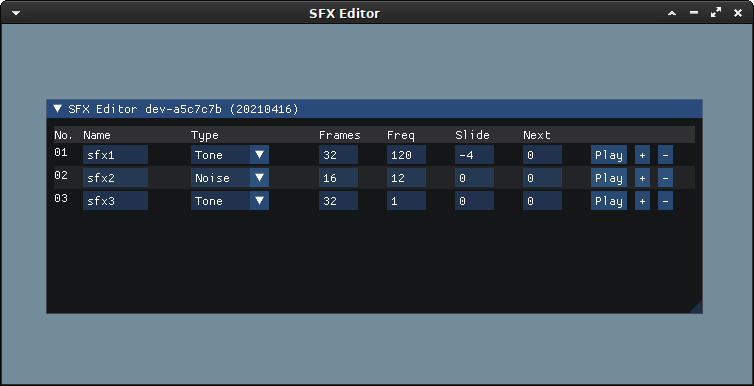
I’ve been working on an engine that is borrowing ideas from the engine used by Steve Turner in games such as Ranarama. Although there’s an disassembly of his routines –allegedly, I can’t confirm that is his code–, I don’t want to use it without permission and I feel it is too complicated and has features that, honestly, I don’t fully understand how to use.
My engine supports two types of sound: tone (square) and noise (random). Both can last for a specific number of frames, support a configurable frequency (that can “slide”), and is possible to link effects.
The engine is small, uses little CPU, and each effect is 4 bytes. Obviously I could support more things, but I feel I can get enough range of sounds to make a game without getting too deep in all the details Turner uses in his engine. The sound quality is low anyway, so for example it is very hard to tell the difference between square and sawtooth waves.
I’m also working on a sound editor, that uses a Z80 emulator library to run the Z80 player and collect sound samples to play the audio on a PC that is very close to what you get on a ZX Spectrum emulator.
I’m not sure how far I’m going to get with this, but it is likely I will release the final product as open source for anyone to use (with out without modifications, so you can change anything you don’t like).
I’ve been posting on Twitter, because after the Brick Rick: Graveyard Shift release I went back to engage; but that will stop and return to very low intensity –I don’t even have a Twitter client on my phone–, because I haven’t changed my mind.
So that means one thing: it is Thursday and that here comes another gamedev update!
ubox MSX lib release
This is a maintenance release that basically fixes a potential problem when changing song with the play function being active in the interrupt handler.
I have used that same code in several games, and you only need to be a bit careful and wait for vsync before changing the song, to ensure that the code will finish before being interrupted. Given that this is a library for others to use, I have decided that it makes more sense to avoid interrupts explicitly.
I had the change in the repo for a while, and I still have a couple of things in my TODO, but the fix deserves a release just in case there is someone out there working on a game.
Targeting the ZX Spectrum 48K
When I was working on “Graveyard Shift” I half added support for 48K games, only that… it wasn’t really working.
The library I wrote for Brick Rick on the speccy is for the 128K models only because it uses double buffer by hardware (and therefore, memory banks), so a lot of code targets 0xc000 as video memory instead of 0x4000.
I have reviewed that code and made a few things configurable:
By disabling the 128K support, all the tables are using the 48K memory addresses; and the bank changing code won’t work –48K models anyway–.
The interrupt setup code is now fully configurable, so for example the 257 bytes table for the Z80’s IM 2 can be located at a high address (on the 128K models can’t be over 0xc000 because of the banks).
At the moment the same library can be configured at compilation time to target 128K or 48K, which is perfect.
I have a work in progress memory map that should work great for 48K games:
Address
Content
5e24 - 6103
Buffer (736 bytes)
6104 -
Code
…
…
e900 - f8ff
Sprite rotation table
f900 - fdfc
Speed sensitive ubox lib code
fdfd - fdff
IM2 jump to ISR
fe00 - ff01
im 2 vector table (257 bytes)
ff02 - ffff
Stack (253 bytes)
This leaves probably too much memory for the library and the stack, but for now I think is fine. I may move non speed-sensitive library code to that 0xf900 address, so I have more space for the game itself.
In my TODO there is also some sort of support to build a 128K version of the game, that should be the same game but adding AY sound. I’m not a fan of that, because I prefer to offer the same experience in all models, but people expect AY sound in 128K models, even if the game is targeting 48K. For now this is low priority, but it shouldn’t be too difficult.
I have a few possible ideas for the game, although it doesn’t need to be necessarily a ZX Spectrum 48K game. In reality I could jump directly into making the game, without having to write any new library code, if I was using my Amstrad CPC or MSX libraries, but I still want to make a speccy game on 48K, so there’s also that!
Crash was a British magazine specialised on the ZX Spectrum home computer, that run from February 1984 to April 1992.
There were a healthy number of magazines back then, and the speccy had very good coverage with several publications dedicated to it, but Crash was one of the most popular –if not the most!– in the UK.
Crash was already back with us, to some capacity, in the form of an annual. But more recently, the same publisher has launched a bi-monthly 60 pages publication in A5: Crash Magazine.
You can buy specific issues from the publisher’s website, or subscribe via Patreon –that has the option for PDF as well–.
I’ve subscribed and read the first two numbers, and I like it very much.
The cover of Issue #2
Looking at the last number (Feb 2021, using the cover of the second issue of the original Crash magazine!), there are three features (Cover crackers, Crash investigates and Crash back), three articles (Simon Buttler’s screens, Dreamworld Poggie, Software house capers), all the regular sections (Editorial, Lloyd Mangram’s Forum –reader letters–, Adventure trail, Nick Robert’s playing tips, Preview and Sign off), and lots of reviews of new games!
I already liked the annuals (I have 2018 and 2019), and this new Crash keeps the good things, and builds on top of them in a shorter and more immediate format.
The reviews are nice and balanced –mostly notable games, why would you like to review a bad game when most of the new releases are free to download and play?–, with the right tone and attitude. The regular sections have a nice “back in the day” feel to them, and the articles are also a good read.
There is some coverage of the ZX Spectrum Next as well, that I must confess I’ve been mostly ignoring until now; and overall I can’t find anything to improve. I couldn’t enjoy the original magazine back in the day, but I’ve been flicking through its pages on archive.org, and this Crash Micro Action feels like a good spiritual successor.
Anyway, I know it sounds crazy that we can still play new games for our loved 8-bit machines, but I must confess that reading a new number of Crash in 2021 was totally unexpected!
I had released this game in 2016, and it was my last game using Z88DK compiler. Back then SDCC was much better, so I changed compiler, but I’m told Z88DK has improved a lot in the latest releases and it is, in fact, the recommended compiler for Z80 microcomputers. I’m too invested in SDCC at this point –in 3 different systems!–, but I really like how Z88DK is evolving.
Anyway, that may not be relevant because I doubt Castaway’s sources compile with a modern release of the compiler –although I made the effort to ensure that it compiles with the appropriate version–, but I wanted to release the source code for two reasons: I had planned to do it for a while, and I read this post by Drew DeVault: the complete guide for open sourcing video games.
May be the title of the post is a bit clickbait-y, but I found interesting that Drew shares some ideas with me:
Video games are an interesting class of software. Unlike most software, they
are a creative endeavour, rather than a practical utility. Where most
software calls for new features to address practical needs of their users,
video games call for new features to serve the creative vision of their
makers.
That’s why I think that most games don’t really work well in a open source development model: release early, release often. Who wants to play an incomplete game in version 0.1.0 to play it again in 0.2.0 because it has some new feature? Although there are exceptions to this, like for example game engines, in general I don’t see the point of open source games.
But then, why did I make Castaway open source? Because what I have done is a code dump, and not really what open source is about.
Drew explains how some open source engines have been very influential –like Id’s engines–, but what finally convinced me to do it was:
Publishing open source games is also a matter of historical preservation.
Proprietary games tend to atrophy. Long after their heyday, with suitable
platforms scarce and physical copies difficult to obtain, many games die a
slow and quiet death, forgotten to the annals of time. Some games have
overcome this by releasing their source code, making it easier for fans to
port the game to new platforms and keep it alive.
This is very relevant looking at current news that Sony’s PS3, PSP, and Vita digital stores may be closing this summer, and in a world where games are “digital only” that means a lot of games will be lost. And we know how many missing in action games we have in our classic platforms, despite the huge community effort to preserve everything.
Although I don’t think my games are at risk of getting lost –I believe most, if not all, have been preserved–, there’s also some value for anyone willing to learn by reading the code, despite not being the best code (I was learning, and Z88DK had its own limitations back then that translates into a lot of includes).
So it is done. Arguably I should be doing the same for the most recent games, but it is difficult; so Castaway is also preparing me to release more current code that is more what I am today instead of what I was as gamedev about 5 years ago. We will see!
The initial import to the git repo was on October 1st 2020, and I tend to do that as soon as possible because my backup is git! If the latest pure development commit was on February 2nd 2021, that was around 4 months.
This is the first long-play that I know of –warning: spoilers–. A quote from the review:
It is tough to come up with something new when it comes to platform games, but this one seems to be rather special for the Spectrum scene. It is a huge and challenging game where you will need to play tactical to defeat the different type of monsters.
The final score is 90%, which is pretty good.
Releasing software is always stressful, there’s no much difference to what I do in my day job, but it wasn’t too bad. Two early bugs that were easy to fix, and it looks like that will be it.
May be software is rarely bug-free, but I call it success if there are no known bugs!
I’ve been thinking how I can unit-test a big part of the code, and my next project hopefully will be verified in a better way, instead of relaying on manual testing only –oh, my games are always very well tested and yet!–. In fact on all my recent projects I’ve settled in a structure that splits logic and presentation (update vs draw), so it sounds possible; and at very least writing the tests will force me to have a deeper look at the code, meaning: less mistakes.
Scala made me change the way I use vim, not only because relying on LSP for code navigation (previously gtags via gen_tags), but because the projects’ directory structure is way more complex than what I used to have in Python.
I used to rely on plain :ed filenameto open files, and then change buffers by just using :b name<TAB> (listing occasionally with :ls and selecting by number with :b number). But enter Scala and, for example, in my Gemini server the code lives in server/src/net/usebox/gemini/server/.
So I ended installing NERDTree and, although I have it always closed and only display the file browser when I need to open a file that I can’t reach immediately by using LSP navigation, it changed the way I work.
For a while I had a partial solution via the :find command. By setting this in my .vimrc:
set path=$PWD/**
In this way :find will search in all sub-directories, for example I can do:
:find filename<TAB><TAB>
But this is far from ideal. It kind of works, but very slowly and is not smart at all, so you get a lot of guff when it tries to find files by scanning all subdirectories (and when you want to open filename.scala you may find that filename.class gets in the way).
Why I didn’t use –or know– the awesome fzf? I can’t tell, but I installed it last night and I’m in love!
Not that I’m going to get rid of NERDTree, but I suspect I’ll use it less and less, because as Tom MacWright puts it in the return of fancy tools:
[…] This is obviously not the future of coding: shouldn’t I be navigating
the source tree in 3D like in Jurassic Park? Sure, but the names of things,
their functionality, and how it all fits together should be things that exist
in one’s mind, not just in a computer.
That resonated with me, because that’s exactly what I was doing in Python, so I tried that fzf tool that he mentions in the post. I guess late is better than never.
I’ve been vim (or neovim) user for around 20 years –can’t say how long exactly, but that sounds about right–, and I’ve tweaked my way of using the editor every now and then, adapting to whatever I’ve been working on at the time.
For example, 5 years ago I was happy writing Python with syntastic and just calling Pydoc from my editor; but now I think I prefer using Python language server, plus some auto-formatting “on save” to conform to PEP8. It’s just a nicer experience.
On that context, I recently gave another go to emacs with LSP Mode, because it looks like the most complete LSP experience around (LSP comes from Language Server Procol), besides I guess using VS Code.
Not that I’m unhappy with vim-lsc, but LSP Mode has support for code lenses (for example), that add some context based operations to your code, such as “run this test”. The LSP server I use for Scala is metals –I don’t think there’s any other option–. It keeps improving on each release, but I’m aware vim-lsc doesn’t support all that metals offers. I just wanted to know what I’m missing.
So basically I gave emacs vanilla a go, after installing from a PPA repo version 26 (my Ubuntu at work only ships up to version 25), and got a very basic emacs configuration, enough to run LSP Mode. And it is nice, although I didn’t see anything that I would consider essential, it was enough to make wonder if I could move full-time to emacs (again; is not the first time I try!).
To make this attempt different, I decided to give Doom emacs a go, because if I need to get my own emacs configuration to the point where I can do the equivalent work I do in vim, is not going to happen. I just don’t have the motivation.
I compiled emacs 27, with only console support –I find the X11 version adds to much latency, and I’m very happy with tmux–, and Doom emacs took around 8 minutes to install with Python and Scala support (both with LSP). That already put me off considerably. To be fair: if I did’t want that level of complexity, I could be using vanilla emacs (but we would go back to not having the time or will power to get all configured).
Long story short: Doom emacs didn’t work for me. Not only because the overwhelming amount of options, but also because after all the steps, I couldn’t get LSP Mode to work as well as I managed to make it work on my hand crafted emacs configuration.
Although I didn’t get anywhere useful, it was a good experience. I think know now that emacs is not the answer to any vim’s shortcomings, because emacs comes with its own issues. So I guess I will give the JetBrains IDE a go, and see if a full IDE is worth it. I suspect is not going to be it, for the comments I hear around me: slow, bloated and complex. oh, isn’t that an IDE?
I was commenting my experience with my team mates, one of them long time emacs user (Clojure guy!) and the other one VS Code user, and the first conclusion was that part of the problem is Scala, or may be its ecosystem, because without the assistance of a smart editor or an IDE, it is very difficult to use third part libraries because the usual complexity of the type system.
The other was that IDEs have got to current levels of complexity (and power, to be fair) because of languages like Java, that really can use the help of such tools.
I know I’m not an IDE person, but I still want to know what is the state of the art, in case there’s anything I can add to my work with vim so I’m perhaps a bit more productive.