Not much to talk about this week, but I thought I would drop a quick note.
First of all, and primary reason why I haven’t done too much gamedev in the last week, I have released a new version of my Gemini server: SpaceBeans.
This release adds classic CGI support, as described in RFC-3875 and slightly adapted to Gemini. For this feature, the obvious inspiration is Jetforce, that is my favourite Gemini server. Instead of coming with my own take on CGI on Gemini, I decided to be mostly compatible with Jetforce, hoping that the more services support things in the same way, the closer we will be to a “standard”. You shouldn’t need to write your CGIs in a specific way to work on a specific server.
I know I wanted to implement SCGI, but classic CGI is simpler and still useful, so I decided to support it first and then, later on, potentially look again at SCGI.
I think I’m happy with the code and the test coverage, although there are some potential improvements that I want to make in a couple of weeks or so. As it is, I think it is usable –although I don’t think anyone is using the server, anyway–.
Then there is gamedev, or perhaps the lack of it.
I haven’t been too inspired. I need some time to think about a clear direction for “Outpost”, because I thought I would get up to speed with the level design, but I’m a bit blocked –sort of writer’s block I guess–. I may continue drawing graphics, but until I have a good plan, the project is a risk of not happening.
Which takes me to another project that is stuck, the CRPG that I’ve been mentioned previously here.
I’m still looking for a formula that I’m happy with and that I’m confident that I can implement on a 8-bit system in a way that I’m happy with it –I have been suggested that perhaps I should target a modern platform, with more or less classic restrictions–.
If I only made games for one 8-bit system, deciding this would be easy, but is not the case. So that means I’m no necessarily looking at the MSX 1 –you heard it here first!–, but it is too soon to talk more about it.
Yes, this update is not too exciting. I will be on holidays next week, that is probably what I need right now!
I use sbt to build Scala projects at work, so trying to learn new things, I decided to use Mill at home. And I’m very happy with it, although it is less mature than sbt, and the user community is smaller.
One of the consequences of the community being smaller is that GitLab provides a template with sbt, but nothing with Mill. Which is OK, because it is very simple; with the exception of setting up the cache –so our builds speed up and we don’t use resources upstream every time we re-download a dependency–.
In reality is not that hard, if you happen to know that Mill uses Coursier instead of Apache Ivy to deal with the dependencies.
I also wanted to generate an artifact (a .jar bundle) every time I make a release, that in my project is just tagging a commit. Then I’ll create the release itself in GitLab and link that artifact to that release –this can be automated as well using GitLab API–.
test: that is run every time I push any commit, and it basically runs the tests.
package: that generates the .jar bundle, but only when there is a tag. Also I want to keep the keep the artifact “forever”, if the build is successful.
The cache is configured to use .cache/ directory –relative to the project directory–, so I set Coursier accordingly.
I use a variable to not repeat the flags passed to Mill, and that’s all!
The other bits I setup in my project are related to Mill itself. I use VCS Version to derive the project version from git, which is perfect given that I use git tags to control what is a release; and I changed the output filename used by Mill –defaults to out.jar– so it can be used directly in the releases.
A way of accomplishing that in Mill 0.9.8 is by adding this to you ScalaModule in build.sc:
val name ="myproject"def assembly = T {val version =VcsVersion.vcsState().format()val newPath = T.ctx.dest /(name +"-"+ version +".jar") os.move(super.assembly().path, newPath)PathRef(newPath)}
It basically replaces assembly with a new command that renames that out.jar to something like myproject-VERSION.jar, integrating nicely with VCS Version.
I have never liked the idea of centralising too many open source projects in the same hosting service. It didn’t go well long time ago with SourceForge and, over the time, I have seen GitHub going a similar route. Then the Microsoft acquisition happened, and I thought that it was unlikely things would change immediately. It is human nature to be lazy, I guess; so I didn’t do anything –because there was no reason, really–.
It has been almost three years, and in reality things haven’t changed much. GihHub has been involved in several controversies over the years, but none of them was enough to make me leave the service, because the network effects are too strong: everybody is in GitHub, a lot of important open source happens there, and the social aspects work because everybody is there.
The last controversy is the launch of a technical preview of GitHub Copilot, that is a machine learning powered autocomplete tool:
GitHub Copilot understands significantly more context than most code assistants. So, whether it’s in a docstring, comment, function name, or the code itself, GitHub Copilot uses the context you’ve provided and synthesizes code to match.
The tool has been fed billions of lines of public code, and in theory it synthesizes the code snippets and should never provide verbatim code, but there is an obvious concern here regarding open source and licenses. Open source doesn’t focus only on having access to the source code, it is the distribution terms what really makes it relevant. The fact that Copilot may not respect the licences is both bad for the original projects and the users introducing code in their own products without permission.
So it is complicated and, in my opinion, what is decided here and now about this matter –and in similar situations related to machine learning–, it will shape how these technologies could change our world.
Perhaps this is not enough to decide to rely less on GitHub, but it is yet another thing, and I have decided to move to a different service that perhaps may be better aligned with my philosophy, and at very least diversify and stop contributing to the centralising trend.
I know I’m going to lose things, specially regarding the social part of the hosting service, because I won’t have stars in my projects –or not that many– to measure popularity, and possibly not that many contributions –although I had close to zero anyway–, but at least functionality wise I’m aiming to have the same.
There are a good number of hosting services for open source projects, and most of them tick all my boxes.
SourceForge: under new ownership, the bad practices seem to be gone.
Launchpad: if I can be blunt, I don’t like Canonical. That’s a story for a different time.
Bitbucket: I like this one a lot as well, I use it for some things –including private repos–, but perhaps it is too close to GitHub ethos.
Sourcehut: very promising service, although it is a bit too different.
Gitea: and others. You can self-host this, but I don’t want to do that for now. Equally, you can find instances of these that accept external projects.
Finally I have decided to give GitLab a go. And I’m not saying that I have fully read (and understood) GitLab’s ToS, and I haven’t compared it with GitHub’s ToS, but the fact that you can download and have a self-hosted version (and it is developed in the open) is something that I like a lot.
For now I have moved two projects that I’m working on actively:
ubox MSX libs: as basic as it goes, git hosting and perhaps will be using issues as well.
Spacebeans: this one uses more features, including CI. Will write a post about that!
I hope this decision doesn’t disrupt too much anyone using these –the MSX libs in reality, nobody cares about my Gemini server–, and I know this is not changing anything in the great scheme of things, but there you go.
Welcome to another Thursday and this week in gamedev.
ZX Spectrum 48K: Outpost
There should have been an update last week, but I recorded 3 sessions, so it felt a bit redundant. You can probably watch the videos –or not, according to YT stats, the average watched time is from 5 to 10 minutes, ouch!–. I’ve improved a lot the collision detection and I have a couple of enemy types, consolidating colour sprites –the second video is interesting–.
The game engine is solid now, although it is missing moving platforms, more enemies, and a special entity to manage item/flag/progress; which is basically the same as keys and doors. And more things I still don’t know it needs.
The last piece of work was related to text encoding. I had implemented 4-bit encoding in maps, to reduce memory footprint by limiting screens to 16 tiles and packing 2 of them in one byte; but the code was optimised (or specific) to that case. Then I did the same for 6-bit encoding, so I could encode a 64 character charset and save 20% of space; but that was already hard.
Turns out I was approaching the problem in the wrong way. I’ve implemented now a general packer that uses a bitstream by converting the bytes to bits, then grouping in 8-bit to get bytes. In this way I can easily encode using any number of bits, including 5-bit –which is what I’m finally using to encode text–.
With 5-bit encoding for text, the idea is to have two charsets of 32 characters, and use a escape code to select the less frequent when needed. It improves almost a 10% over the 6-bit encoding.
All this because I plan to use terminals in the game to give information to the player. This can be very effective, if done well. It can be used to tell a story –which should help to keep player’s engagement, like I did in Dawn of Kernel, clarify what I mean –sometimes puzzles can be misunderstood–, and even as part of the gameplay –where to go, what to do–.
The game will be 48K anyway and the amount of text will be limited, so the less space it uses, the better.
I’ve been drawing tiles as well, and I’m starting with game design. It is difficult when you have an empty map, but usually things start to get in place as soon as you start working on specific sections. I have a vague idea of what is going on in the game, but it needs more time until is complete.
Other ideas, other things
I have a couple of ideas in background, but other than preparing a template for Amstrad CPC games, I haven’t progressed any of them.
Why I haven’t done a template repo before? Good question! Bootstrapping a new project is always tedious, and my experience releasing my MSX libraries has forced me to organise the code better. So I guess this will make more likely that I can try a quick idea to see if it works or not, without committing a couple of gamedev sessions. I’m not sure if this is 100% positive, I’ve been focused on one project for quite some time, having side projects may or may not be a good thing!
Speaking of MSX, the tools in ubox MSX libs are now documented. When I was documenting it, I realised how difficult was to explain how some of these work, and that means it is very unlikely anyone was using them. I wonder what other things are missing for people to make new games. Let me know!
Obviously, the part about it being the start of season 2 is a joke (isn’t it?), but I’ve uploaded a new video to my coding sessions.
I mentioned this in my latest weekly update, that I feel like recording a few of these, partially because some of the videos of my original experiment are OK and partially because they may work as motivation to keep working on my projects. Sharing my progress has always worked for me, not only because of the feedback –positive and negative–, but also because gamedev as a solo developer can be a bit lonely.
I have reviewed my OBS setup to make things look a better –and 1080p!–. I have only one screen, so it is awkward, but definitely better than the previous videos. Hopefully going back to make these periodically will help me to tweak my settings to improve the result, as opposed to making a video every few months and not remembering how things work –and that’s why the previous video back in January sounds terribly bad–. Not that is too important, considering that the content will be the same –me coding–.
This week has been very varied, with some unexpected things potentially happening!
ZX Spectrum 48K: Outpost
I have a working title for my ZX Spectrum game: Outpost.
I finally decided to not use the title I was planning for the cancelled sequel to Castaway, although I really like it. Unfortunately it would require a good amount of story to explain it, and Outpost is direct, makes the actual place a character, and according to Spectrum Computing the name is not taken –not that is too important, unless is a well known game–.
I drew the title for menu, and for now that’s it.
The menu (colour cycle not shown)
Another thing that I got out of the way is the map encoding. I’ve implemented metatiles in a way that is not too annoying, thanks to a good amount of Python.
The basic idea is that I keep a tileset image and a metatiles image. When processing them, I generate the tileset normally –the monochrome data, and a tile/attribute map, all tiles of 8x8 pixels–, and a table that translates 2x2 meta tiles (16x16 pixels) to indexes in the tile/attribute map. The converter will find the 4 tiles that are part of a metatile by matching image data.
Then in tiled I draw my screens using the metatiles, and the game will expand them to use regular tiles before drawing, collision detection, etc. The result is very clean, and the only bit that is slightly cumbersome is having to keep both tiles and metatiles images in sync when I’m just trying graphics, but is not too bad and eventually both tiles and tilesets will be stable and it would be just level design.
It is hard to tell exact numbers, but looking at my test screens, the map data went from around 100 bytes to around 50 bytes, without limiting in the level design –other than the number of metatiles, but being 4 bytes per metatile, I don’t thing it will be a problem–.
There’s also the space used by entities, and there aren’t much savings there, so I calculated how many screens I can include in the game, and I’m aiming at 80 or 90. It should fit!
I’ve started with the level design already, stopping to implement engine features as I need them, and the game is starting to look good!
Things going cold, and a possible comeback
Unfortunately the MSX RPG is on hold, or shall I say cancelled? As I mentioned previously, I got to the conclusion that what I think that would work with MSX 1 restrictions is either:
not looking good –in my humble opinion–, so it is putting me off.
not the game I want to make.
although it may work, it would require a lot of graphics that I can’t draw.
Being a type of game that is likely to be a long time commitment, I can’t keep putting time on it unless I’m reasonably certain that I can finish the game.
That doesn’t mean all the bits I have done already are wasted, because I’ve learnt a few things and it is likely that I know another 8-bit system that it would be a better match for this project –sorry, is not the MSX2; there are a few RPGs on that system and I’m not sure I would be able to contribute anything new–.
On the MSX camp, I had several contributions to ubox MSX libs –all from Pedro de Medeiros; thank you!–, and those have reminded me that I didn’t document the tools used to build the example game.
In reality I wasn’t sure if I wanted to document those, as they are not really required to build games, but Pedro is keen to use them, and is not always obvious how they work. It is still a work in progress, but I hope the tools will be fully documented soon.
Finally, it is possible that “@reidrac is CODING” videos may have a comeback –second season?–. My inspiration has been on and off lately, and after a while, I must confess some of the videos I recorded aren’t too bad. It is possible that making very focused videos may spice things a bit and help me to get things done.
First of all I want to clarify that in this post I’m focusing on 8-bit games, but you can find similar controversies and attitudes around makers in any gamedev market (see Game Maker Studio or Unity, for example).
It is a bit unfortunate that there is a lot of gatekeeping in the retro-community, and it has many forms: people that advocate using only the real hardware –dismissing those aficionados that use emulators, or even FPGAs–, what type of screen you must use (CRTs vs anything else), games must push the machines to their limits –if the game is fun or not, who cares?–, or that true gamedevs use ASM. Without being an excuse, I understand that this is a hobby and people are passionate and intense about it. And the gatekeepers are extremely loud!
As you can see, I’m also biased –everybody is, as long as you have an opinion–. Perhaps I’m in the let people enjoy things camp, which I hope can’t be considered gatekeeping.
One of the recurrent topics in all these discussions is how games made with makers –tools or frameworks that help you to make games, for example AGD or The Mojon Twins’ MKs–, are looked down as less quality games.
And it is true that you can find games that aren’t great, but that’s not necessarily because the way they are made, but because other reasons. It could be because the author didn’t use an original idea, or didn’t know how to use the tools, or directly because they reused too much from the basics that the tools offer, resulting in a game that it too similar to other games made with that tool. It could be as well that you don’t like the game.
However, in my opinion, that doesn’t mean it is because the tools –although they may have limitations, like any game engine, like I do have my own limitations as programmer because of time, interests or skills–. When you are playing a game and you are having fun (or not) you can’t say that is is because the tools that were used to make it, and that’s because those tools allow a wide range of results, all depending on the author’s skills using it.
Sure, you can have a flickering mess than moves slowly on the screen and ruins any chance of enjoyment, but the truth is that those cases are very unlikely because these makers tend to have a more than acceptable technical level –although I’m sure any tool, doesn’t matter how good it is, can deliver terrible results in the wrong hands–.
We got to the point where a very atmospheric game such as Nosy for the ZX Spectrum gets a good score on Crash Micro Action #2 (90%, with a Crash Smash!), and people complain and argue that the score is too high because the game was made with a maker. Apparently there are even people saying that any game made with a maker should have a 20% penalty, under the argument that it is unfair to compare this game –again, made with a maker– with masterpieces such as Aliens: Neoplasma.
(Edit 2021-06-09 19:00:00 BST: I’m referring to what I’ve been told, despite the original post not saying exactly that. The complaint was about the score and the Crash Smash, and the fact that the game was made with the MK1 engine was used to support the opinion that it is an average game. The post suggested that the score should be reduced by a 20% in all categories, and not that all games made with makers should score less. That was the origin of the controversy around Nosy, and it adds to the usual criticism of makers –and the community drama–. The post in question can be read in FB’s Crash Annual and Magazine public group)
We are living a new golden age for the 8-bit microcomputers. Despite being past their time, we keep getting new games, that are made by people putting a lot of love on them. And because people do things for love –most of these games a free as well–, you have games targeting the ZX Spectrum 48K, ZX Spectrum 128K, ZX Spectrum Next –I can hear gatekeepers screaming “that’s not a Spectrum!”–, or even games that use modern hardware add-ons such as Dandanator cartridges. All at the same time, with some people stuck in 1985, others in 1990, and some others living in the future! How can you compare all those games in different time-lines?
I don’t feel like deciding here how Crash reviews should be written, even if I have an opinion and not always agree with the reviews –which, by the way, is just another opinion–. I’m just happy that they exist, and the same goes with all those makers and people making games with them. Please, don’t stop!
I wish we could have a bit less gatekeeping, so everybody was welcome no matter how they want to enjoy this hobby. We can all help, by politely asking to those shouting to be a bit quieter.
After implementing support for floating bus –that at the end works in all models, with fall-back to vsync; useful for clones and inaccurate emulators–, I continued adding features to the engine:
Tweaks to the jump and gravity.
Collision detection for the enemies, so the player can lose lives and die.
Pick ups, that will be an important component in the game (key/door puzzles).
One special pick up: “the blaster”. I’ve decided to replicate the behaviour I used in Castaway, so the blaster needs time to charge between shots. In Castaway that was to hide a limitation of the engine, but in this game I like it because it adds strategy!
And, of course, lots of fixes (with new bugs introduced, probably).
Some of these features were difficult to implement. This is the first time I’m working with a XOR engine –the sprites are drawn using the XOR function, and erased applying the same function with the same exact sprite–, and works well, but it is tricky to add or remove entities mid-loop.
At the end the solution was clean: I just needed to adjust the process by adding an extra draw or erase when I add or remove an entity mid-loop. For example: when the player uses the blaster, the game loop expects the projectile sprite to be there to be erased before drawing the next frame, so I have to perform one extra draw so there’s something to erase.
This is done sometimes out of sync, or waiting for the floating bus if is a big change –for example: erase an enemy that is being destroyed and draw the first frame of the explosion–, and in general the result is very nice. Not completely perfect when the drawing happens on the top of the screen, but this is one of the cases where aiming for perfection wouldn’t be useful.
Currently I only have implemented the “extra life” and the blaster pick ups, and any other is just added to the inventory –not really, is just drawing them in the HUD–. I added support for persistence via a bitmap, so those items don’t respawn and I can check for the specific bit as a flag to see if the player has collected that pick up.
For now the enemies respawn when you leave and re-enter the screen, but I may experiment with some ideas. For example: the enemies’ respawn could be conditional, making the game a bit more interesting and opening the door to some exciting game design.
I’m trying to decide what I’m going to do with the game map. I started using a basic 8-bit per tile map with compression, like in Brick Rick (for the ZX Spectrum), because it is easy and allowed me to progress with the engine, but the screens use a bit too much memory. That wasn’t a problem with Brick Rick because I was aiming to the 128K models, but this game is 48K.
I have used different approaches in different projects, so at this point I don’t think I’m going to find anything ground-breaking that I haven’t used before. It is more about deciding that I’m going to be happy with the restrictions the encoding will introduce. For example, Kitsune’s Curse uses packing with 4-bit per tile plus some programmatic definitions of the map, with the downside of having to define tilesets of 16 tiles –not the end of the world, but makes level design a bit harder–.
I have some ideas that are a variation of what I used in Brick Rick (for the Amstrad CPC this time), but I’m not too excited because it is an encoding that would make using tiled less nice, although it could reduce the maps about 50% compared with current memory wasting encoding.
Meanwhile, the game doesn’t have a name yet. It is more and more likely that it will be a sequel –or prequel?– to Castaway, so perhaps I should use the name I had planned for that: Starblind.
More MSX RPG
I have started exploring a bit of code for that crazy idea of making a CRPG –which I guess is more a western role playing game than a classic JRPG; oh, labels!–.
Currently I have a nice menu system, but I’m struggling with the MSX1 restrictions; and I don’t want to use MSX2. Which is not a complete waste of time, because I’m getting to the conclusion that I should focus on what is that the MSX can do, and then implement the mechanics I want for the game.
Later on I could get the core of the engine and, perhaps, use a different 8-bit system to implement the game I had in mind initially. But that sounds like a project for next year, so we will see!
A couple of days ago I added some sound effects to my ZX Spectrum 48K “work in progress” game, and I found that the few cycles the beeper engine uses in the interrupt handler broke my tight timing and, specially on the top of the screen, there will be flicker when drawing a few sprites on the same line. Which is a shame.
Initially I thought that it wasn’t a big deal but, because how I decided to implement coloured sprites, the flickering is specially ugly –to my eyes, at least–. So I knew about a technique that allows you some extra time besides the one you get by syncing with the interrupt: The Definitive Programmer’s Guide to Using the Floating Bus Trick on the ZX Spectrum, by Ast A. Moore.
From that page:
In the context of the ZX Spectrum, the floating bus trick refers to exploiting a hardware quirk of these machines, where a value being read by the ULA from the data bus can also be read by the CPU.
Which in a nutshell means you can prepare some specific data on screen, usually in the colour attributes, and listen to the ULA using the floating bus trick to sync with it when it is processing that specific data.
For example: in my game I have drawn a “HUD” –head-up display; in a computer game, the part of the screen that shows information like the number of lives left or the score– with a specific colour attribute not used anywhere else in the game, and then I have a specifically timed routine that listens the floating bus to wait until the ULA is processing those attributes. Because the attributes are in the bottom of the drawable screen, I get extra time to draw my sprites –the HUD and the bottom border–.
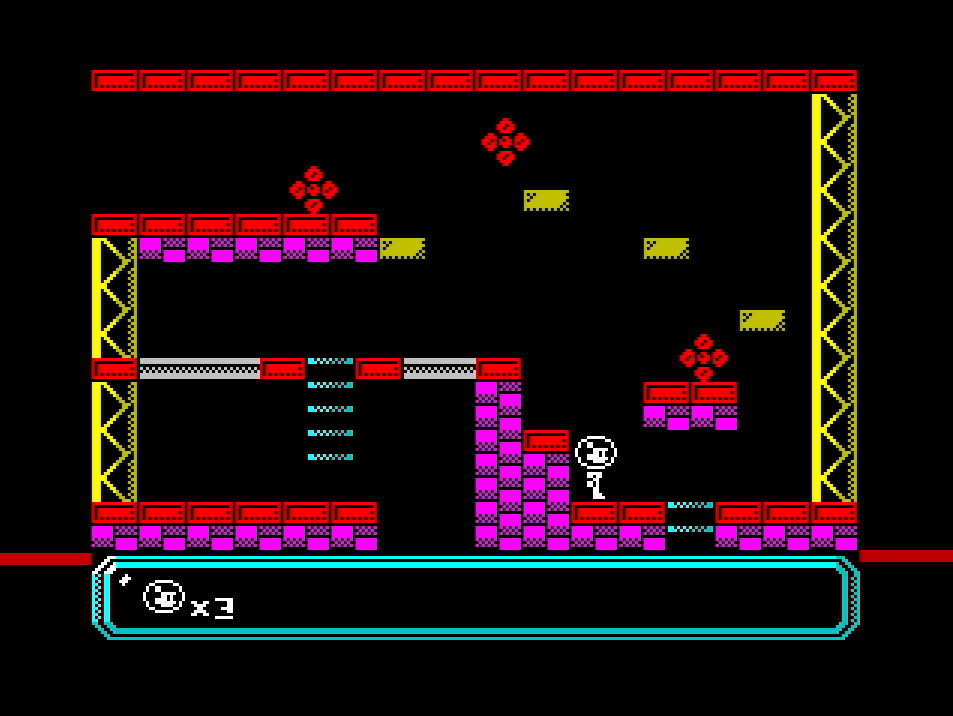
Testing my routines
On that screenshot of the game I’m drawing a red line on the border when I sync with the HUD attributes after listening to the floating bus. And with that extra time, the flickering is gone!
Initially it was thought that this trick didn’t work on +2A/+3 models. I had a +2A back in the day and I can confirm that a lot of games –specially for 48K models– didn’t work on my machine. Ast did some excellent research a few years ago and he came up with an implementation for those models. It only took 30 years!
Just as an example –you should read Ast’s article–, this is my current version of the code:
; HUD attr: bright paper cyan, black ink
; will OR 1 in +2A/+3 models
BUS_ATTRequ0x68wait_bus:
lda, (0x0b53)
cp#0x7e
jrz, other_buswait_bus_loop:
lda, #0x40
ina, (0xff)
cp#BUS_ATTR
jpnz, wait_bus_loopxoraretother_bus:
lda, (#0x5800)
lda, #0x0f
ina, (0xfd)
cp#(BUS_ATTR | 1)
jpnz, other_busxoraret
It looks like the floating bus is tricky to implement on emulators. The “classic” floating bus is perfectly emulated by almost all emulators, but the floating bus of the +2A/+3 models is not widely supported. I don’t have an list, but I have confirmed RVM and CLK support it fine!
I detect the +2A/+3 models and just branch to the special sync code for them. If the floating bus is not there, the code will loop forever. That could be avoided by detecting if the floating bus exists before hand and falling back to use vsync –even if that means flickering sprites–, but that’s probably not necessary as it works in real hardware and most emulators using 48K models.
Oh, looks like it is Thursday again. Let’s see what happened in my gamedev time!
Unnamed programming language
As I mentioned in my previous update, I was investigating a scripting solution, but somehow I got distracted in the process. Which is OK, sometimes these distractions lead to good things.
So far I’ve implemented a recursive descent parser for a C-alike language –although I’m using something closer to Scala syntax–, and I can go through the abstract syntax tree and generate something.
And that was fun, but I need to start writing tests and perhaps emit code so I can prove that my language design makes sense.
If I want to use this in any of my 8-bit projects, I probably want to generate something that is useful in those cases. I could compile to Z80 ASM that integrates well with SDCC tools, which sounds very hard –and very interesting at the same time–; or perhaps bytecode for a simple VM, which is probably easier and a more achievable task.
But then I thought that writing the VM itself would be a non-trivial amount of work, so I had the “brilliant idea” to generate WAT (WebAssembly Text), which looks like ASM that can be compiled to be run in a WA (WebAssembly) virtual machine. And so far has been very interesting, and not as complicated as I was expecting. It is also useful that the nuances of generating code to run on WA are helping me to refine the language design, even if that means I’m also being influenced by WA.
This is a code example:
def fac(acc:dword, n:dword):dword{if(n ==0) acc;else fac(n * acc, n -1);}fac(1,10);
I got to a point where the WAT generation has “revealed” some inconsistencies in my language design and I need to revisit it, which is perfect, because it means the project can grow with less chances of getting to a dead end.
I’m implementing it all in Python with type hints and mypy via a Python LSP server, and I’m really enjoying the experience. Initially I thought the type annotations were slowing me down, but in reality it was all my fault because my code wasn’t great. Now it feels a lot like writing Scala, and it is saving me a lot of time by finding bugs early –plus the better code design to make mypy happy–.
I don’t have a name, and is not a problem; but surely a name would be useful if this project has any future.
More ZX Spectrum 48K coding
Arguably this went a bit cold. Firstly because I spent some time writing a beeper engine, and after that because writing a compiler –see previous point– is fun!
In reality I was thinking about it, because I need a game idea before I can make the game itself. I’m still undecided, but I’m leaning towards a platform game, probably what “Starblind” was going to be before I moved into a more top-down multi-directional scroll idea, that was kind of interesting as a tech demo, but there was never a proper game idea behind it. I’m not looking to make a genre-shaking game, only something that is fun to play and has a good speccy 48K vibe.
I’ve been planning on how to encode the map data reducing the memory footprint as much as possible. In Brick Rick on the speccy 128K I had lots of memory, so I didn’t bother doing anything smart –just good old compression–; but that won’t do it in a 48K game, even if the engine itself doesn’t use a lot of memory. For now I have some ideas on paper, but it is a bit too early to start writing a prototype.
Other than that, I’m trying to clarify what are going to be the features supported by the game engine. So far far I have:
Flick-screen platforming action, probably with object based puzzles.
A large map area, or at least not small.
Different sprite sizes; I’m testing a spaceman sprite that is 16x24 pixels, but enemies are likely to be 16x16.
Colour sprites for the enemies, because the type of sprites I’m using, the background will be mostly black; so it makes sense to use coloured sprites.
No buffering, drawing directly on the screen!
And that last point is what has kept me busy this week, mostly.
I knew that my sprite routines aren’t the fastest you can write, but Brick Rick uses hardware double buffer (I write to the back-screen, and swap with the visible screen when finished), so it didn’t matter at all because the game updates a 16FPS, so updating 1 of every 3 frames leaves more than enough time to update the game state and draw.
In this project I don’t have that nice hardware support, and I don’t have memory either! So I’m reducing scope, for example, by using XOR sprites (instead of masked) and limiting the backgrounds (mostly black). But the sprite routines aren’t fast enough to draw enough things in one frame, so I was getting flickering all over the place.
Although I’m still testing, I’ve decided to do something similar to Brick Rick’s approach: if you can’t update all the screen in one frame, that’s fine because our target is not the 50 frames per second but 16. The only difference is that I don’t have a back buffer to compose the scene and then make it visible in one step –or fast enough so there is no flickering–. But, what if I can spread the updates in several frames?
If you run the game slow enough you can see that the sprites are drawn on the screen in groups –or at least that’s what I meant!–, but because all the game state is updated at the same time, is not noticeable.
This is not a technical marvel, is more about hiding that my sprite routines aren’t fast enough. Combined with some code to sort the sprites so the groups are optimal, I can move a good number of thins on screen without any flicker –most of the time, at least!–.
So far I’m happy. I’ll keep testing and if it is confirmed that this idea is stable enough, that may be the base for the game engine!